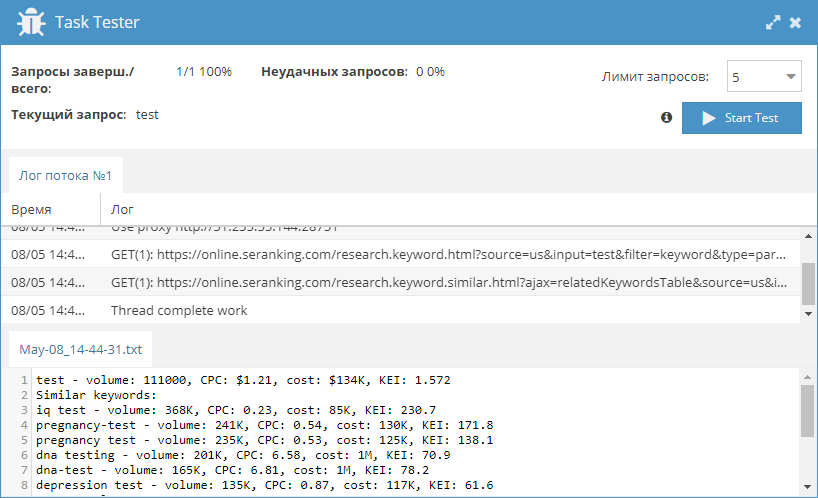
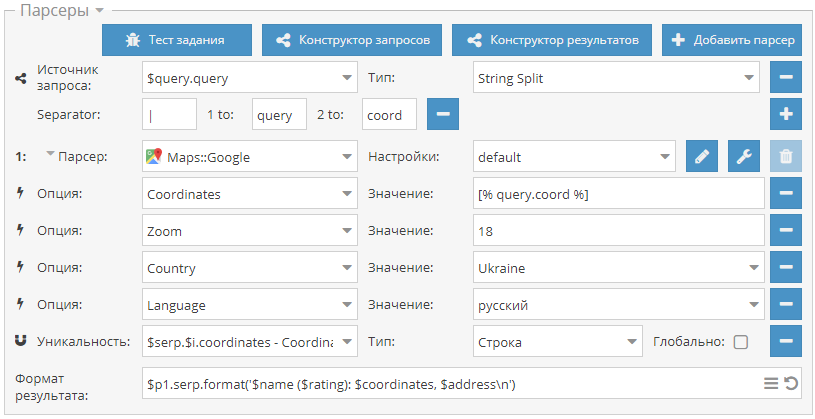
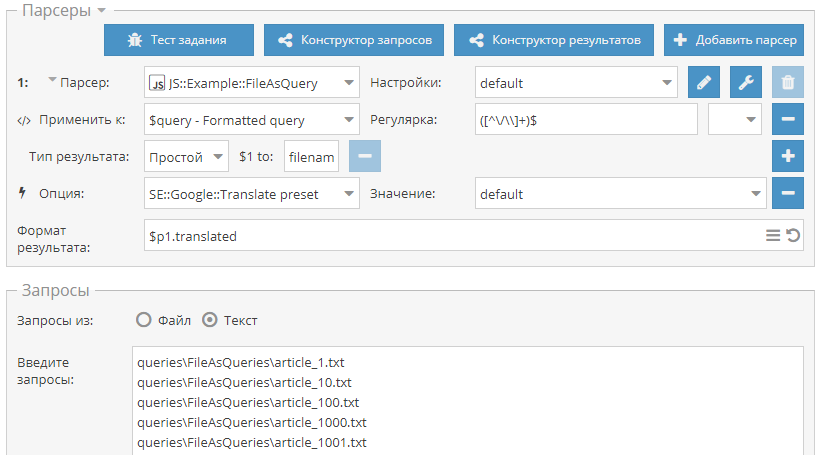
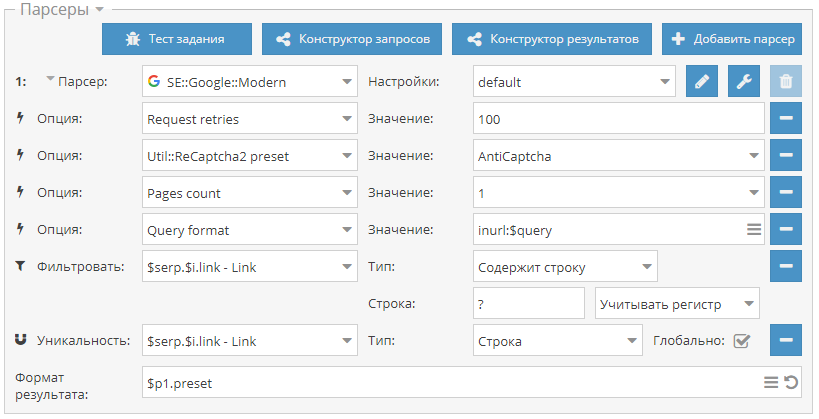
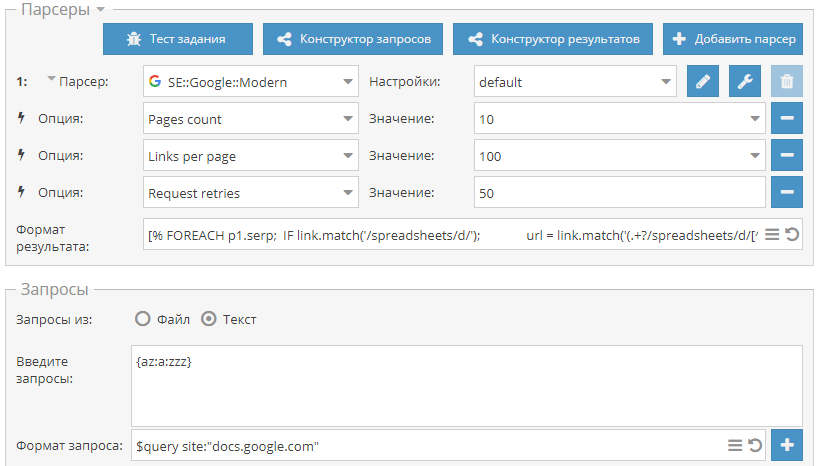
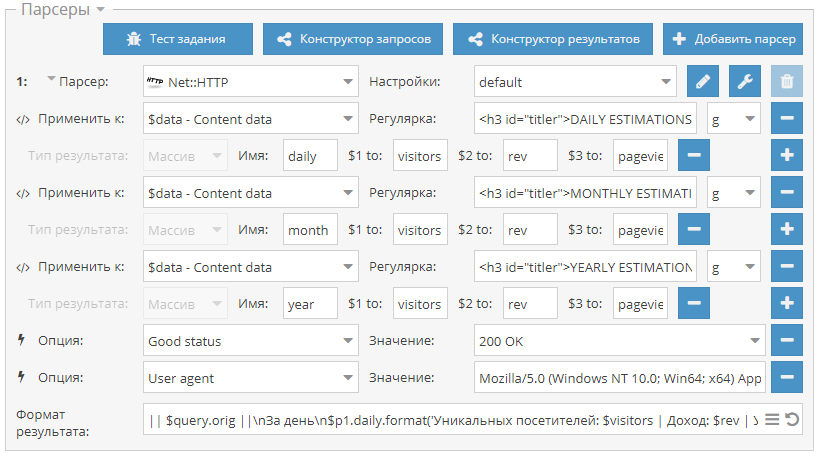
1.2.434 - множество улучшений и новых возможностей в парсерах, оптимизация работы, поддержка SOCKS4

Улучшения
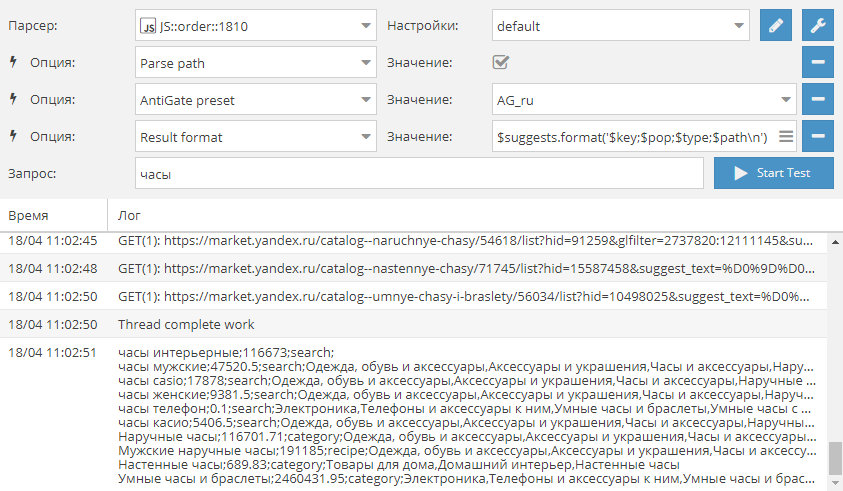
* В SE::Yandex добавлен парсинг значков
* В SE::Google::Modern добавлена опция Disable autocorrect, которая позволяет отключить автоисправление Гугла и парсить выдачу именно по указанному запросу
* В SE::Yahoo добавлен выбор страны, языка и Safe Search, обновлен список доменов
* В Net:: DNS добавлена возможность выводить записи любого типа
* В Rank::MajesticSEO добавлена проверка контента и поддержка сессий
* Значительно улучшен SE::Google::Suggest, добавлены новые возможности
* В SE::IxQuickдобавлен параметр Family filter, позволяет выбрать уровень фильтрации
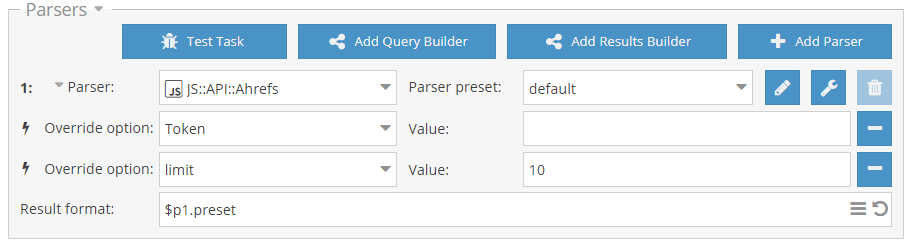
* В Shop::Amazon добавлена возможность парсить количество продавцов для каждого товара
* Теперь в SE::Yandex при получении 404 кода ответа парсер будет повторять попытку, также улучшена проверка контента
* Теперь в Rank::SEMrush при получении 403 кода ответа прокси будет баниться
* Добавлена поддержка SOCKS4 прокси
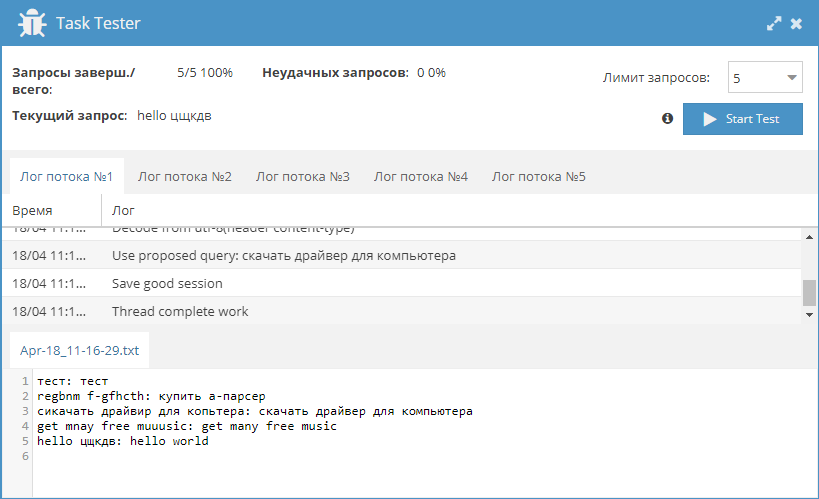
* Оптимизирована загрузка и сохранение конфига и файлов заданий
* Улучшена скорость загрузки JS парсеров
* Уменьшено использование памяти в JS парсерах
* Улучшение производительности при использовании сокетов в JS парсерах
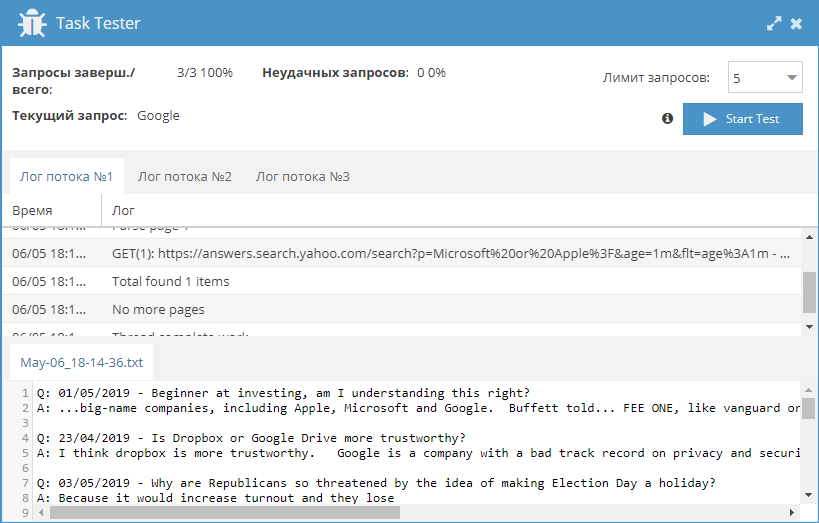
Исправления в связи с изменениями в выдаче
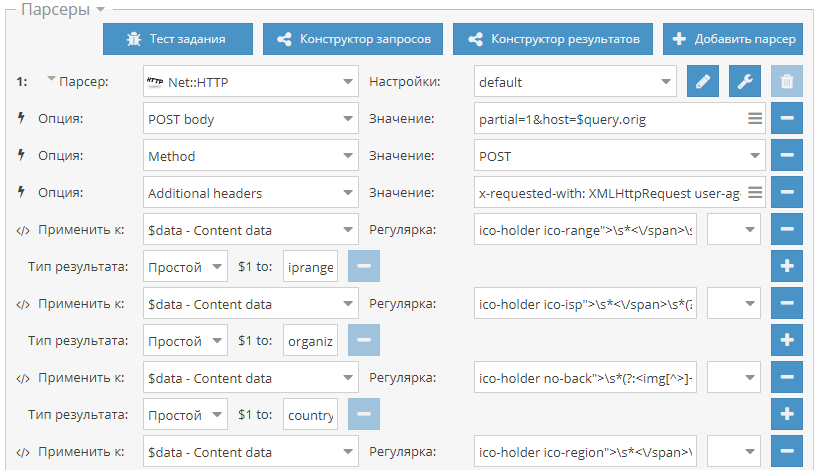
* В SE::Google::Modern исправлен парсинг анкоров
* В SE::Yandex::Images парсинг начинался со 2-й страницы
* Исправлен парсинг ссылок в SE::Baidu
* Исправлен парсинг countries в Rank::SEMrush::Keyword
* SE:: DuckDuckGo, SE:: DuckDuckGo::Images, SE::IxQuick, Shop::Amazon
Исправления
* В SE::Google::Modern исправлена проблема, при которой запрос считается неудачным при использовании Parse not found
* Исправлена обработка пустой выдачи в SE::Yandex
* Исправлена проблема, когда SE:: DuckDuckGo не парсил запросы в которых больше 1 слова
* JS парсеры: исправлена работа setTimeout на Windows
* Исправлен ряд ошибок, которые появились в процессе оптимизации парсера
Улучшения
* В SE::Yandex добавлен парсинг значков
* В SE::Google::Modern добавлена опция Disable autocorrect, которая позволяет отключить автоисправление Гугла и парсить выдачу именно по указанному запросу
* В SE::Yahoo добавлен выбор страны, языка и Safe Search, обновлен список доменов
* В Net:: DNS добавлена возможность выводить записи любого типа
* В Rank::MajesticSEO добавлена проверка контента и поддержка сессий
* Значительно улучшен SE::Google::Suggest, добавлены новые возможности
* В SE::IxQuickдобавлен параметр Family filter, позволяет выбрать уровень фильтрации
* В Shop::Amazon добавлена возможность парсить количество продавцов для каждого товара
* Теперь в SE::Yandex при получении 404 кода ответа парсер будет повторять попытку, также улучшена проверка контента
* Теперь в Rank::SEMrush при получении 403 кода ответа прокси будет баниться
* Добавлена поддержка SOCKS4 прокси
* Оптимизирована загрузка и сохранение конфига и файлов заданий
* Улучшена скорость загрузки JS парсеров
* Уменьшено использование памяти в JS парсерах
* Улучшение производительности при использовании сокетов в JS парсерах
Исправления в связи с изменениями в выдаче
* В SE::Google::Modern исправлен парсинг анкоров
* В SE::Yandex::Images парсинг начинался со 2-й страницы
* Исправлен парсинг ссылок в SE::Baidu
* Исправлен парсинг countries в Rank::SEMrush::Keyword
* SE:: DuckDuckGo, SE:: DuckDuckGo::Images, SE::IxQuick, Shop::Amazon
Исправления
* В SE::Google::Modern исправлена проблема, при которой запрос считается неудачным при использовании Parse not found
* Исправлена обработка пустой выдачи в SE::Yandex
* Исправлена проблема, когда SE:: DuckDuckGo не парсил запросы в которых больше 1 слова
* JS парсеры: исправлена работа setTimeout на Windows
* Исправлен ряд ошибок, которые появились в процессе оптимизации парсера
 ) - отписывайтесь
) - отписывайтесь